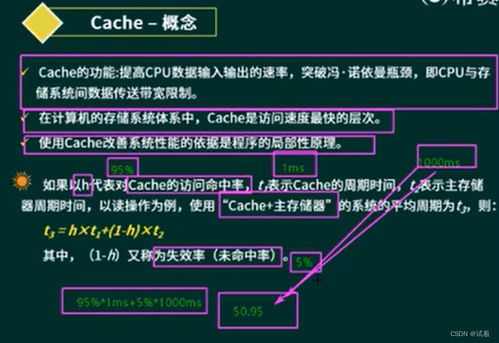
隨著高校招生規(guī)模的持續(xù)擴大,傳統(tǒng)招生管理方式面臨著數據量大、處理效率低和實時性差等問題。為了解決這些挑戰(zhàn),我們設計并實現了一個基于Spark的招生系統(tǒng)。該系統(tǒng)利用Spark框架的高性能分布式計算能力,結合現代大數據處理技術,構建了一個高效、可擴展的招生管理平臺。
系統(tǒng)設計概述
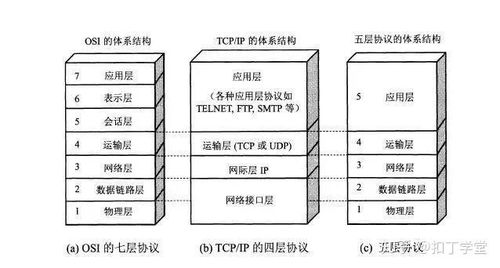
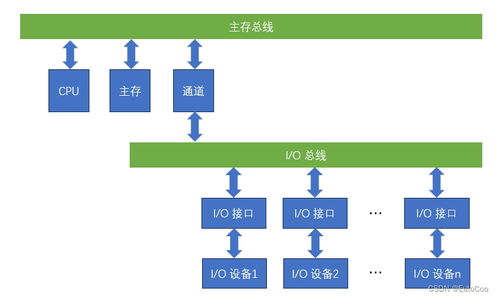
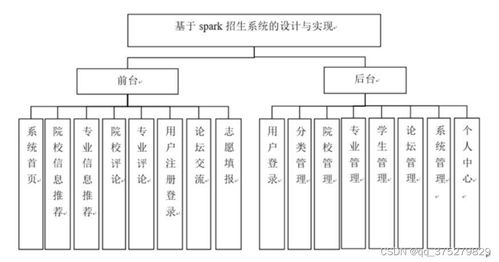
本招生系統(tǒng)采用分層架構,包括數據采集層、數據處理層、業(yè)務邏輯層和用戶界面層。數據采集層負責從各種來源(如在線申請表單、歷史數據庫)收集招生相關數據。數據處理層基于Spark的核心組件(如Spark Core和Spark SQL)實現數據的清洗、轉換和分析,通過分布式計算提升處理速度。業(yè)務邏輯層封裝了招生業(yè)務流程,包括申請?zhí)峤弧①Y格審核、錄取決策和數據統(tǒng)計等功能。用戶界面層提供友好的Web界面,支持招生管理員和申請者進行交互。
核心技術實現
在實現過程中,我們使用Spark的DataFrame API進行數據操作,結合HDFS或云存儲進行數據持久化。系統(tǒng)通過Spark Streaming支持實時數據流處理,例如監(jiān)控申請高峰期流量并動態(tài)優(yōu)化資源。利用MLlib庫實現了簡單的機器學習模型,如預測申請者錄取概率,為決策提供數據支持。代碼采用Scala編寫,確保與Spark生態(tài)的無縫集成。系統(tǒng)集成了安全機制,如數據加密和訪問控制,以保護敏感信息。
畢業(yè)設計源碼與文檔
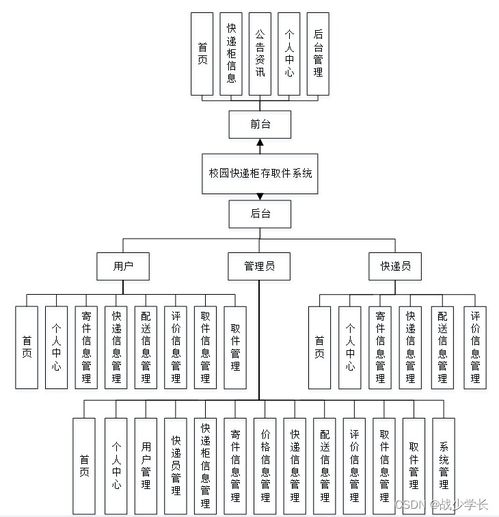
本項目的源碼和文檔(lw文檔)已完整提供,包括系統(tǒng)架構圖、模塊設計說明、代碼實現細節(jié)和部署指南。源碼覆蓋了從數據導入到結果輸出的全流程,文檔詳細闡述了計算機系統(tǒng)服務的集成方法,例如如何與現有校園系統(tǒng)(如學籍管理系統(tǒng))對接。通過該設計,學生可以深入理解大數據技術在教育領域的應用,提升計算機系統(tǒng)服務的實踐能力。
應用與優(yōu)勢
實際測試表明,該系統(tǒng)顯著提升了招生數據處理的效率和準確性。相比傳統(tǒng)系統(tǒng),基于Spark的實現能夠處理百萬級數據,并在分鐘內完成復雜查詢和統(tǒng)計分析。這不僅減輕了人工負擔,還支持了數據驅動的招生決策。系統(tǒng)可擴展至更多功能,如智能推薦和移動端支持。本設計展示了Spark在大數據系統(tǒng)開發(fā)中的強大潛力,為計算機畢業(yè)設計提供了有價值的參考。